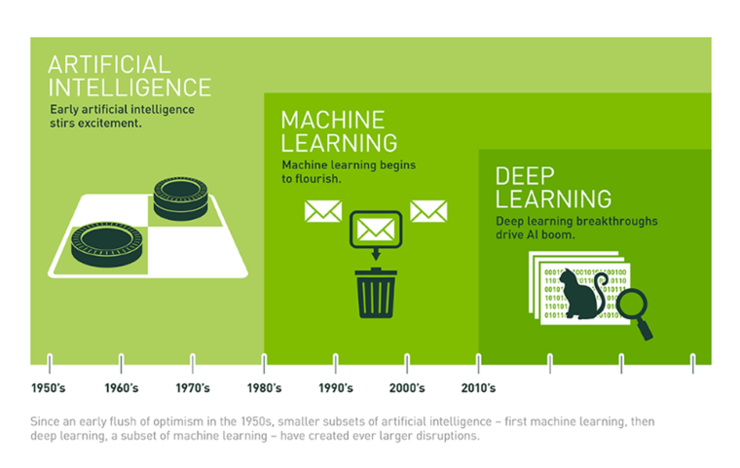
* 인공지능 기술의 탄생 및 성장
- 탁월한 병렬 처리 기능의 GPU 도입: 2015년 이후 신속하고 강력한 병렬 처리 성능을 제공하는 GPU의 도입으로 더욱 가속화되고 있다.
- 빅데이터 시대: 갈수록 폭발적으로 늘어나고 있는 저장용량과 이미지, 텍스트, 매핑데이터 등 모든 영역의 데이터가 범람하게 된 '빅데이터' 시대의 도래도 이런 성장세에 큰 영향을 미쳤다.
* 인공지능(Artificial Intelligence, AI): 인간의 지능을 기계로 구현하다
- 인공지능은 기계로부터 만들어진 지능을 말한다. 컴퓨터 공학에서 이상적인 지능을 갖춘 존재, 혹은 시스템에 의해 만들어진 지능, 즉 인공적인 지능을 의미한다.
- 세개의 단어(AI, ML, DL) 중 가장 넓은 의미이다.
- 인간의 감각, 사고력을 지닌 채 인간처럼 생각하는 인공지능을 General AI라고 하지만, 현재 기술 발전 수준에서 만들 수 있는 인공지능은 Narrow AI 개념에 포함된다.
- Narrow AI는 이미지 분류 서비스나 얼굴 인식 기능 등과 같이 특정 작업을 인간 이상의 능력으로 해낼 수 있는 것이 특징이다.
* 머신러닝(Machine Learning, ML): 인공지능을 구현하는 구체적 접근 방식
- ex) 메일의 스팸을 자동으로 걸러주는 역할
- 기본적으로 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단이나 예측을 한다.
- 궁극적으로는 의사 결정 기준에 대한 구체적인 지침을 소프트웨어에 직접 코딩해 넣는 것이 아닌, 대량의 데이터와 알고리즘을 통해 컴퓨터 그 자체를 학습시켜 작업의 수행 방법을 익히는 것을 목표로 한다.
- 알고리즘 방식에는 의사 결정 트리 학습, 귀납 논리 프로그래밍, 클러스터링, 강화학습, Bayesian 네트워크 등이 포함된다.
- 이 중 어느 것도 General AI를 달성하진 못했고, 초기 머신러닝 접근 방식으로는 Narrow AI 조차 완성하기 어려운 경우도 많았다.
- 머신러닝은 인공지능을 구현하는 과정에서 일정량의 코딩 작업이 수반된다는 한계점에 봉착한다.
- 가령 머신러닝 시스템으로 정지 표지판 이미지를 인식할 경우, 개발자는
1) 물체의 시작과 끝 부분을 프로그램으로 식별하는 경계 감지 필터
2) 물체의 면을 확인하는 형상 감지
3) 'S-T-O-P'와 같은 문자를 인식하는 분류기 등을 직접 코딩으로 제작해야 한다.
- 이처럼 머신러닝은 '코딩'된 분류기로부터 이미지를 인식하고, 알고리즘을 통해 정지 표지판을 '학습'하는 방식으로 작동된다.
- 머신러닝의 이미지 인식률은 상용화하기 충분한 성능을 구현하지만, 안개가 끼거나 나무에 가려 표지판이 잘 안보이는 특정 상황의 경우 이미지 인식률이 떨어지기도 한다.
- 기존의 C/C++, Java 등의 프로그래밍과 같이 프로그래머가 상황이나 조건에 따라 하나 하나씩 행동이나 결과값을 주어야하는 explicit programming(명시적 프로그래맹) 방법이 아닌, 데이터를 통해 학습하는 능력을 컴퓨터에게 주는 것을 말한다.
- 예를 들어, 계산기를 만든다면 explicit programming으로 깔끔하고 에러 없이 만들 수 있다.
- 하지만, 개와 고양이 이미지 분류 시스템은 기존 explicit programming을 이용한다면 개와 고양이라는 동물을 알려주기 위해 수없이 많은 경우의 수를 따져야 한다. 또한, 이렇게 많은 경우의 수와 규칙을 만족하는 알고리즘을 개발하는 것은 어려운 일이다.
- 이러한 경우 explicit programming 방식을 사용하지 않고, machine learning을 사용한다면 뛰어난 성능을 보일 수 있다.
- 머신러닝은 다시 Supervised Learning(지도학습), Unsupervised Learing(비지도 학습), Reinforcement Learning(강화학습)으로 나누어진다.
1) 지도 학습
지도 학습은 쉽게 말해 기계에 정답을 가르쳐주는 학습이다. 지도 방법에는 크게 Classification(분류)와 Regression(회귀)가 있다.
(1) 분류(classification) - discrete value
1, 2, 3이라는 숫자를 분류하기 위해, 1, 2, 3이라는 숫자가 써있는 이미지들을 여러장 준비하고, 각 이미지에 해당하는 정답 label 들을 준비한다. 만약 이미지에 1이라고 그려져 있으면, 그 이미지의 정답 label은 숫자 1의 값을 가진다. 이런 labeled된 데이터를 이용해 기계에 학습시킨다.
(2) 회귀(regression) - continuous value
만약 우리가 원하는 시스템에 f(1) = 1, f(2) = 2, f(3) = 3을 만족하는 시스템이라고 하자. 여기에 6을 input으로 넣으면 output 값이 어떻게 될까라고 하면 아마 6이라고 대답할 것이다. 이렇게 "f(1) = 1, f(2) = 2, f(3) = 3" 이라는 f를 학습시켜, 6이나 다른 임의의 숫자를 넣어 어떤 값이 나올지 예측하는 것을 회귀라고 한다. 학습시킨 후 예측하고자 하는 Input이 5.5, 6.7등 다양한 숫자가 될 수 있다.

2) 비지도 학습
비지도 학습은 지도 학습과 달리 input data에 label이 되어있지 않다. 정답이 없는 data를 Input으로 사용한다.
즉 비지도 학습의 목적인 데이터의 정답/오답이 아니라 입력 데이터들 사이의 어떤 관계, 패턴에 관심이 있다는 것이다.
비지도 학습은 주어진 데이터를 비슷한 특성끼리 묶고 데이터 군집간의 특징을 살펴보는 데 목적이 있다.
이는 clustering(클러스터링)이라고 하는 비지도 학습의 일종이다. 이 외에도 차원축소, Hidden Markov Model 등이 있다.

3) 강화 학습
강화 학습은 알파고에 적용된 기술이라고 생각하면 된다. 강화 학습은 agent 혹은 system이 어떤 환경(Environment)에서 어떻게 동작하는지 모른다. 그래서 행동(action)을 취하고 그에 상응하는 보상(reward)을 얻으며 보상에 해당하는 행동이 강화되면서 학습해 가는 과정이다.
즉, 학습의 방향은 agent가 보상을 최대화 하도록 학습을 진행하는 방향이다.

* 딥러닝(Deep Learning, DL): 완전한 머신러닝을 실현하는 기술
- 딥러닝은 perceptron에 근거한 인공신경망(artificial neural network, ANN)의 일종이다.
- 인공 신경망(artificial neural network)에 영감을 준 것은 인간의 뇌가 지는 생물학적 특성, 특히 뉴련의 연결 구조였다.
- 예를 들어, 이미지를 수많은 타일로 잘라 신경망의 첫 번째 레이어에 입력하면, 그 뉴런들은 데이터를 다음 레이어로 전달하는 과정을 마지막 레이어에서 최종 출력이 생성될 때 까지 반복한다.
- 그리고 각 뉴런에는 수행하는 작업을 기준으로 입력의 정확도를 나타내는 가중치가 할당되며, 그 후 가중치를 모두 합산해 최종 출력이 결정된다.
- 충분한 데이터를 바탕으로 가중치에 따라 결과를 예측하는 확률 벡터(probability vector)가 활용된다.
- 딥러닝은 인공신경망에서 발전한 형태의 인공지능으로, 뇌의 뉴런과 유사한 정보 입출력 계층을 활용해 데이터를 학습시킨다.
- 신경망 네트워크는 학습 과정에서 수많은 오답을 낼 가능성이 크다. 정지 표지판의 예로 돌아가면, 기상 상태, 밤낮의 변화에 관계 없이 항상 정답을 낼 수 있을 정도로 정밀하게 뉴런의 가중치를 조정하려면 수백, 수천, 어쩌면 수백만개의 이미지를 학습해야 할지도 모른다. -> 이정도는 되어야 제대로 된 학습이라고 할 수 있다.
- 2012년, 구글과 스탠퍼드의 Andrew NG 교수는 1만 6,000개의 컴퓨터로 약 10억개 이상의 신경망으로 이뤄진 Deep Neural Network(심층신경망)을 구현했다.
- 컴퓨터가 영상에 나온 고양이의 형태와 생김새를 판단하는 과정을 스스로 학습하게 한 것이다.
- 딥러닝으로 훈련된 시스템의 이미지 인식 능력은 이미 인간을 앞서고 있다.
- 이 밖에도 딥러닝의 영역에는 혈액의 암세포, MRI 스캔에서 종양 식별 능력이 포함된다.
출처: [NVIDIA] 인공지능과 머신러닝, 딥러닝의 차이점을 알아보자
'Machine Learning & Deep Learning' 카테고리의 다른 글
| Active Learning이란 (0) | 2020.09.16 |
|---|---|
| 머신러닝 Loss Function 이해하기 (0) | 2020.03.03 |
| 딥러닝 프레임워크 - Tensorflow vs PyTorch (0) | 2019.12.18 |


