* 강연 정리
1) GPU under the hood: deep learning practitioners' perspective
첫 번째 강연은 딥러닝 어플리케이션 성능을 분석하고 이해하는 방법에 대해 설명해주셨다.
<주제>
Operation Speed
- Latency
- Throughput
Model Accuracy에 대해서가 아닌, latency와 throughput 성능을 통해 서비스 퀄리티를 향상시키고(response time 향상), GPU를 효율적으로 이용할 수 있는 방법에 대한 내용이 주제였다.
<Training Performance>
- CPU와 GPU의 관계

CPU는 GPU에 data를 보내서 연산을 시키고, 연산된 결과 데이터를 GPU가 다시 CPU로 보낸다.
- Model의 forward, backward pass를 보면, 각각의 layer의 operation은 GPU의 CUDA kernel에서 계산된다.
< Categories of Deep Learning Kernels>
- Element-wise kernels(memory > computation): ReLU, scale, add, and so on
- Reduction kernels: Batch Normalization, Softmax, etc.
- Dot-product kernels(memory < computation): matrix-vector or matrix-matrix multiply kernels such as FC and CONV
<Compute Bound vs. Memory Bound>
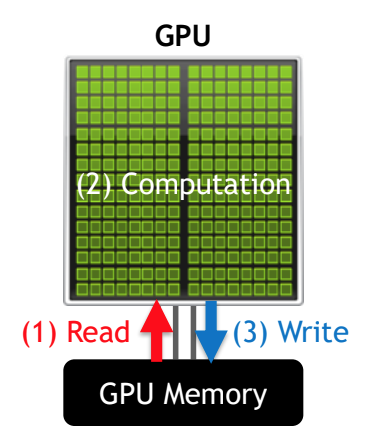


- Compute Bound: Compute utilization > Memory utilization
즉 computational problem을 해결할 때, 시간을 주로 계산하는데 쓰냐(compute), memory를 사용하는데 쓰냐(memory)인데, compute bound는 계산하는데 걸리는 시간이 문제를 해결하는데 주로 차지하는 시간이라는 의미이다.
- Memory Bound: Compute utilization < <Memory utilization
Memory bound는 computational problem을 해결할 때, memory를 읽어오고 적재하고 사용하는 등의 memory utilization에 주로 시간이 많이 걸린다는 의미이다.
위의 내용을 확인해서 CUDA kernel이 GPU를 효율적으로 쓰고있는데 맞는지 확인한다
만약 효율적으로 GPU를 사용하고 있지 않다면, 퍼포먼스를 향상시키기 위해 high-level guidance가 필요하다

- Latency Bound: Both utilizations are low
kernel이 충분히 병렬처리(parallelism)가 잘 안되었을 수 있다.
checkpoint 1) kernel의 thread 블록 수가 충분한가(gridDim)
checkpoint 2) 각각의 thread block 안에 thread 수가 충분한가(blockDim)
<Thread blocks and streaming multiprocessors>

- 충분한 thread blocks이 있는지 어떻게 알아내는가
- GPU는 block 안에 여러개의 streaming multiprocessros(SM)을 가지고 있다
- GPU를 효율적으로활용하기 위해서, SM들은 최소 한 개 이상의 thread block을 가져야하고, 아니면 gridDim은 SMs의 수에 배수여야 한다.
- SM들은 여러개의 thread blocks에 할당될 수 있다(16개까지)
- thread block 크기가 32의 배수가 아니거나, 32보다 작으면 비효율적이다
- gridDim은 input shape에 의해 달라진다
<Matrix Multiplication>
- output matrix는 tiles들로 쪼개질 수 있고, 이들은 thread blocks에 할당된다
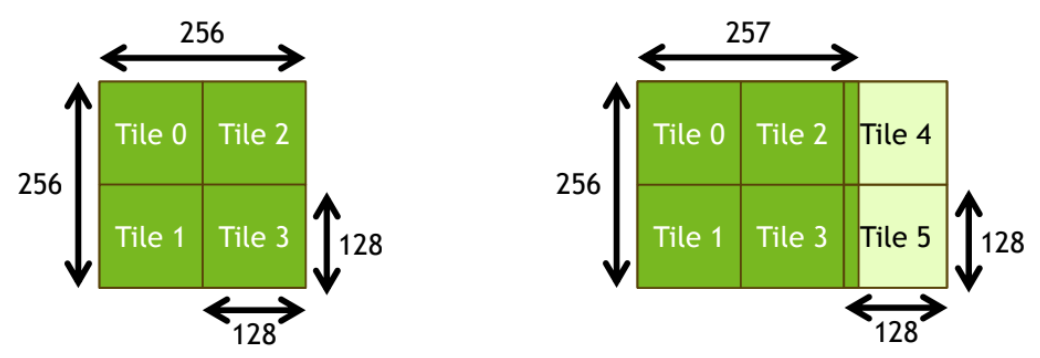
- matrix dimensions이 tile dimensions으로 잘 쪼개지지 않을경우, 몇몇 thread(ex. tile 4, tile 5)는 inactive 되거나 compute resources를 낭비할 수 있다.
- Typical tile sizes: 256x128, 128x256, 128x128, etc
- 따라서 딥러닝에서 이미지 사이즈를 8의 배수로 해주면 좋다 !!
<Fully Connected Layer(FC Layer)>
- matrix multiplication으로 표현 가능하다

- 큰 batch size일수록, inputs과 outputs이 병렬화(parallelism)이 더 잘 되고 퍼포먼스도 더 나아진다
- 8의 배수로 input, output 선택하는게 좋다
<Convolutions>
- 역시 matrix 곱으로 표현된다
- N(batch size), P(output height), Q(output width)를 늘리면 parallelisim and performance가 향상된다
- C와 K를 8의 배수로 하는게 좋다

<Batch Size>
- 가장 중요한 파라미터 중 하나이다
- batch size를 늘리면 무한정으로 성능이 증가하는 건 아니지만 performance, parellel에 이득이다
- GPU 성능 때문에 많이 못늘릴 대도 있다
- Mixed Precision Training이 도움이 될 것이다.
--> FP32 + FP16으로 섞어써서, 필요한 메모리 사이즈 줄어드는 효과가 나고, 주어진 시간 안에 많은 메모리 읽고 쓸 수 있다.
--> 따라서 batch size를 크게 설정할 수 있다
--> 필요로하는 memory bandwidth가 줄어든다 - memory bound kernels(such as ReLU)의 속도가 빨라진다
<Fallacy>
- nvidia-smi
- nvidia-smi's GPU utilization은 efficiency, 즉 효율성을 나타내는 것이 아니고 사용하고 있는지 아닌지를 나타내주는 것이다
- 주어진 시간 안에 GPU 돌고있나, 없나만 확인한다
(e.g., a long running 1-thread kernel can make GPU-Util 100%)
- The utilization can be useful to check if a given GPU is idel
<When GPU can be IDLE?>
- GPU idle time은 언제인가
- Some DL operations는 CPU에서만 가능할 때(e.g., tf.sparse.segment_sum)
- Input data loading and/or prerocessing

<Characteristics of Inference>
- inference: training과 다르다, gpu가 상황에 따라 다를 수 있다, batch size도 다를 수 있다
(예를 들면, V100s으로 training하고 T4로 inference 할 수 있다)
- Backward pass가 없다
- Inference-specific optimization이 필요하다
<Kernel Fusion>
- Kernel Fusion은 성능을 향상시킨다 - 왜?
- 예시: Kernel 0, 1, 2, 3 -> Fused kernel 0-3 (4개의 커널을 한개로 합침)
- Forward passdpaks wlqwndgkf tn dlTek
- 실제 kernel 4개를 도는동안, 트랜지스터를 붙잡고 안놔줄 수 있기 때문에 memory 읽고 쓰는 횟수가 줄어든다(more effective bandwidth utilization)
<Hiring!>
- Cutting-edge techiniques in DL/ML에 대해 연구하고 개발하신다고 한다.
- GPU architectures에서 best possible permormace를 내기 위해서, 깊은 분석과 optimization을 진행한다고 하신다
- GPU를 이용한 practical한 문제를 key developer들과 함께 직접적으로 함께 이해하고 문제를 해결해볼 수 있다
출처: NVIDIA DEVTECH 이민석님 발표자료



