이번 강연은 multi-gpu를 활용하는 방법에 대한 이야기이다.
* NVIDIA AI TECHNOLOGY CENTRE (NVAITC)
- 미주 제외 지역에서 연구하는 그룹(Singabpore, Malaysia, Indonesia, Thailand, India, China, Korean, Japan)
* APEC OPP란?
- Python extension
- multi-gpu를 활용하는 방법이다
* Race to conversaional AI
- model size가 증가하면서, 네트워크의 parameter가 bilions을 넘고있다
* 현재 SOTA 모델들의 추세

- Upstream raw에 정보, 데이터를 때려넣는다. 큰 데이터를 큰 머신으로 돌려야한다
- Downstream task, task(분야)는 바뀌지만 model은 바뀌지 않는다
- distill: 작은 task mpdel, 극단으로 network를 줄인다
* Incredible scaling as workloads expand

- 1500개의 GPU까지 함께 쓰면 성능이 향상된다는 것을 확인하였다
- data parallel: 쉬움
- model paralle: 어려움
- 장비 + 모델 + 설치: 설치시 ngc.nvidia.com 참고하기
* Multi-gpu로 data-parallel 하는 방법
- data parallel + model parallel = data and model parallel
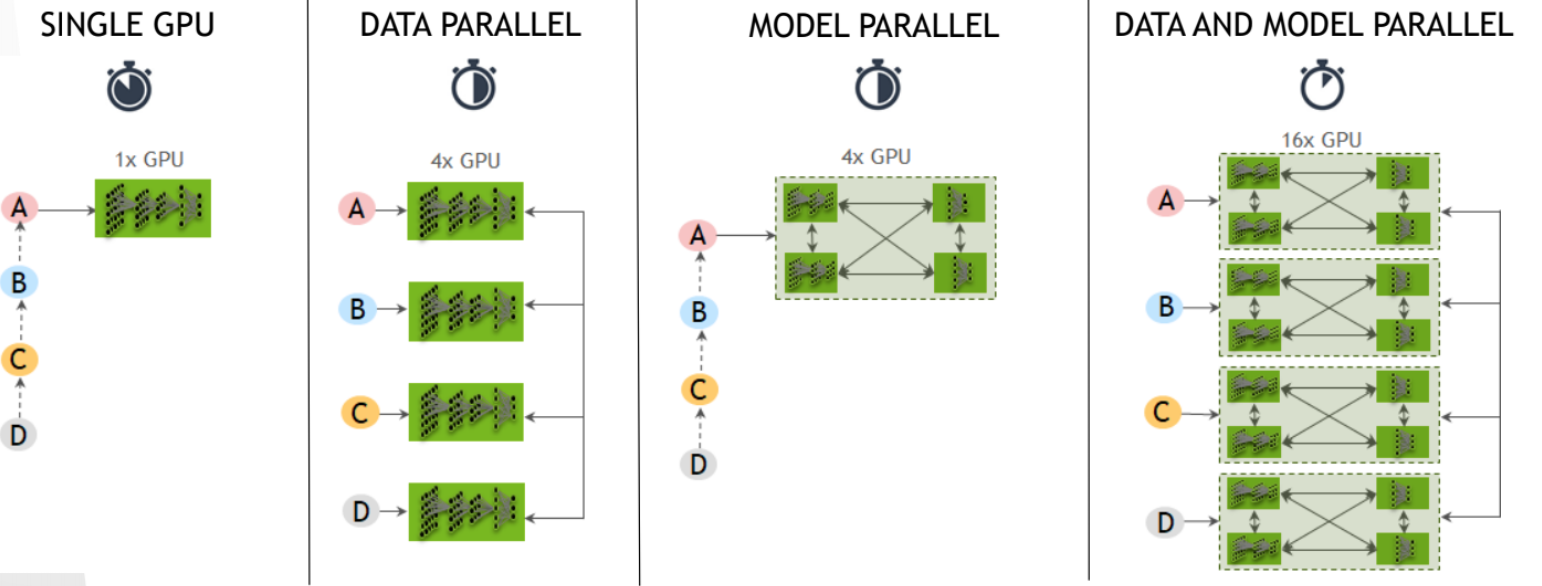
- 병렬 계산, N 코어만큼 나눠서 계산하고 최종 결과는 각 코어에서 reduction(OpenMP, OpenACC)
* DL data Parallel
- 데이터를 분할 -> 대부분 독립 계산 -> 통신전략(reduce, broadcast)
* 접근 방법
- PYTORCH DataParallel (DP)
--> mini-batch로 나눠서 mini-batchs들을 parallel하게 돌린다.
--> memory sharing
- PYTORCH Distributed Data Parallel (DDP)
--> module level에서 구현된 data parallelism이다.
--> torch.distributed package를 통해 synchronize gradients, parameters, and buffers
--> paallelism은 process 간에, 아니면 process 안에서 모두 가능하다
--> DataParallel과 비슷하다
- APEX (NVIDIA custom DDP)
--> apex.parallel.DistributedDataParallel: module wrapper. 이것은 DDP와 비슷하다(torch.nn.parallel.DistributedDataParallel)
--> optimized for NVIDIA's NCCL
* torch.nn.DataParallel
- 많은 community code(pytorch 구현)에서 DataParallel 조차 사용하지 않는다고 한다
- PYTORCH DataParallel(DP)
- Model만 DataParallel로 감싸주면 pytorch가 알아서 작업
import torch
form torch import nn
form toruch.uitls.data import DataLoader
if args.cuda:
model.cuda()
if args.parallel:
model = nn.DataParallel(model)
- 단점
--> 0번 GPU 메모리 사용량 증가 및 0번 GPU 부하발생 (타 GPU memory 비효율적으로 사용)
--> 통신량이 늘어날수록 성능저하 발생 (4GPU 이상)
- DP 메모리 이슈 우회 방법
--> 0번 GPU에는 batch size를 0으로 주거나 아주 작게 준다 (github의 transformer-xl 코드 참조)
* torch.nn.parallel.DistributedDataParallel
- 동일 프로세스이면 DP와 DDP가 동일하게 작동한다
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.nn import DataParallel as DP
if args.distributed:
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda(args.gpu)
args.batch_size = int(args.batch_size / ngpus_per_node)
args.workers = int(args.workers / ngpus_per_node)
model = DDP(model, device_ids=[args.gpu])
else:
model.cuda()
model = DDP(model)
else:
model.cuda()
model = DP(model)
* APEX 활용
import torch.distributed as dist
from torch.nn.modules import Module
from torch.autograd import Variable
class DistributedDataParallel(Module):
...
1. APEX source build 사용
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
2. NGC 사용 (apex included)

3. Custom script
APEX의 distributed.py 혹은 multiproc.py만 가져다 사용
* 마지막 말씀
- 딥러닝 공부할 때, 작은거라도 몽땅 다 짜보는게 도움이 많이 된다고 하셨다
- 깃팅만, 즉 git을 보고 베끼기만 하면 안된다는 것이다
- 나한테 현재 필요하다고 생각되는 것만 잘 말씀해주셨다. 바닥부터 공부하기!
출처: 모든 자료의 출처는 NVAITC 유현곤님 발표자료에서 가져왔습니다



