* 주제
- Edge computing을 필요로 하는 이유, Edge computing에 딥러닝까지 적용하고 싶은 이유
- Edge computing에 딥러닝을 적용하기 위해서 겪는 어려움
+ Edge computing에 대해서는 처음 들어보는 내용이라 제대로 이해하지 못한 부분이 대부분이었다 ㅠㅠ
* Edge Computing이란
<Edge라는 단어의 의미는?>
- End device
- Edge(Intelligent Edge/Edge Intelligence)
<Edge computing 등장 배경>
- 클라우드 컴퓨팅 탄생 이후 문제점이 발생하였고, 이를 해결하고자 edge computing 개념이 등장했다.
- 기존 클라우드 컴퓨팅 방식이 데이터 센터가 물리적으로 떨어져 있는 곳에서 데이터 처리와 연산을 중앙 집중형으로 관리하는 방식이라면, 엣지 컴퓨팅은 사용자의 IoT 단말기들과 근접한 위치에 있는 각각의 기기에서 발생하는 개별 데이터를 분산 처리, 분석하여 활용할 수 있다.
- 말단 기기에서 컴퓨팅을 수행하는 것을 의미한다.
- 클라우드 컴퓨팅은 데이터를 처리하는 곳이 데이터 센터에 있는 반면, 엣지 컴퓨팅은 스마트폰과 같은 장치에서 데이터를 처리한다.
- 엣지 컴퓨팅은 분산된 개방형 아키텍쳐로서 분산된 처리 성능을 제공하여 모바일 컴퓨팅 및 IoT 기술을 지원한다.

- 엣지 컴퓨팅을 통해 대기 시간 없이 실시간 데이터 처리를 지원할 수 있다.
- 클라우드 컴퓨팅을 이용하면, 생성된 데이터를 클라우드로 전송하고 전송받은 클라우드에서 데이터를 가공했다면 엣지 컴퓨팅은 스마트 애플리케이션 및 장치에서 데이터가 생성될 때, 즉각적으로 데이터에 대응하여 전송 시간을 줄여준다.
* Edge Computing의 장점
- Latency: 대기 시간 없이 실시간 데이터 처리 지원 가능하다
- Privacy: 클라우드 컴퓨팅은 중앙 서버 아키텍쳐로 데이터 전송/전달 보안 강화해야 하지만, 엣지 컴퓨팅은 데이터 수집과 처리를 자체적으로 처리하기 때문에 클라우드 컴퓨팅에 비해 보안이 좋다
- Scalability: 해당 기기에서만 발생하는 데이터를 처리
- Reliability: 클라우드 컴퓨팅을 사용하면, 서버가 마비될 시 치명적 타격을 입지만 엣지 컴퓨팅을 사용하면 자체적으로 컴퓨팅을 수행하기에 장애에 효과적으로 대응 가능하다.
- Efficiency
- Cost
* 고려해야 될 요소들
- Accuracy/Latency tradeoff
- Bandwidth
- Power consumption
- Maintenance/Sustainability
* 딥러닝을 적용하기 어렵게 하는 요소들
- High resource requirement
- Bandwidth limitation
- Power limitation
- Monetary cost
* Methods
<Model: Accuracy vs Efficiency>
- 초기부터 현재까지는 기본적으로 정확도를 높이는 방향으로 발전
- 정확도 향상을 위해 모델을 개선하다 보면 모델의 크기가 계속해서 커지고, 이에 따른 효율성의 문제 발생
- 정확도가 높아도 모델이 너무 무겁고 느리면 실제 상황에서 적용하기 어렵다
<Efficiency>
- 목적에 따라 Cost는 줄이고, Speed를 올리기 위해 Quality의 손해를 감수하기도 한다
- Cost와 Speed가 어느 정도 정해져 있는 상태에서 성능을 올려야 할때 (한정된 자원에서 모델을 키워야 될 때)
- 빠른 학습이 필요할때 (같은 리소스에서 더 많은 데이터를 학습하고 평가하기 위한 경우)
- Accuracy & Efficiency 모두 고려하는 방향으로 model architecture 설계해보자
<Software tools for each Hardware>
- 하드웨어별 지원 S/W
--> Intel's OpenVINO
--> Nvidia's EGX
--> Qualcomm's Neural Processing SDK
--> RSTensorflow
- 범용 S/W
--> Tensorflow Lite
--> ONNX (Open Neural Network Exchange format)
<Edge server Computation>
- real-time에서 큰 DNN 필요 (power, computation, memory issue)
- Straightfoward offloading이 주로 사용된다 (DNN 연산을 분산하지 않는다)
- Data Preprocessing
--> 딥러닝 기반 시스템에서는 고전적 방식의 feature extraction 형태 전처리는 자주 사용하지 않는다
--> 불필요한 데이터와 연산을 최소화 하는 목적을 가지고 전처리를 한다
ex) Blurry image remove, ROI crop, change detection
- Edge resource management
--> 여러 디바이스와 서버가 동시에 연결되어 있는 시스템에서는 획일하게 연산을 나누거나 스케쥴링 하는 것은 비효율적이다
--> 가용한 모든 리소스에 대해 최적화를 하여 효율을 극대화 해야한다
--> shared compute resource를 "accuracy/latency tradeoff"와 더불어 "# of request" 등의 추가적인 metric를 이용하여 해당 문제를 해결
<Computing Across Edge Devices>
- Edge server가 DNN을 가속화 해주지만 항상 Edge server만을 이용할 필요는 없다
- 적절한 offloading을 하는 것이 효율적이다
- offloading이란? 데이터베이스 서버에서 처리하던 일을 스토리지 계층으로 옮겨서 처리하는 개념이다
1) binary offloading
--> offloading을 할지말지
--> data size, hardware capability, DNN model, network quality, accuracy/latency tradeoff, energy,monetary cost 등에 따라offloading 여부 결정

2) partial offloading
--> 하나의 모델을 나누어서 다른 장치들에서 연산
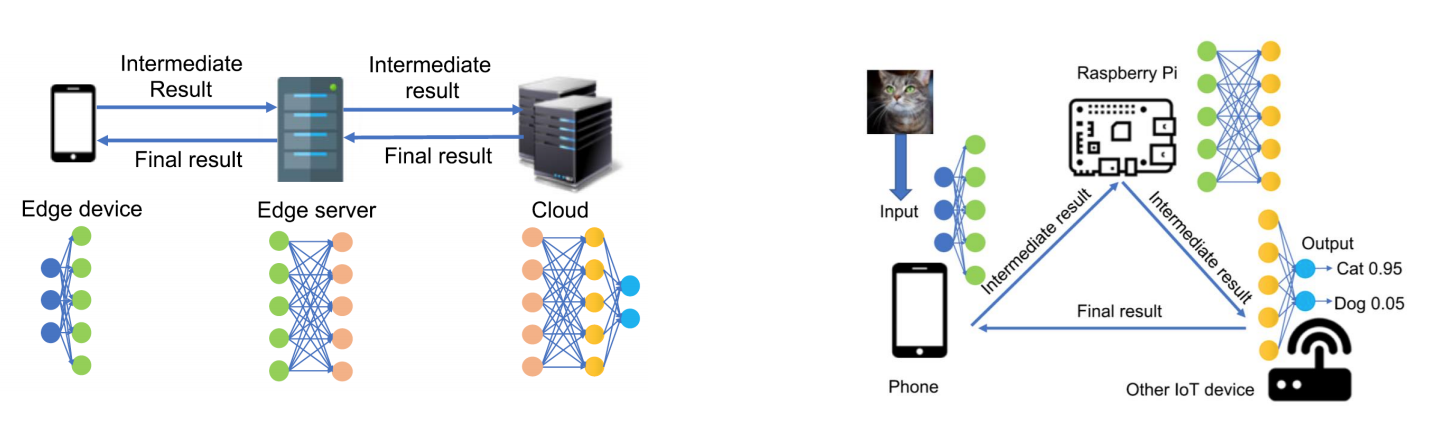
3) hierarchical offloading
--> 하나의 모델을 edge device, edge server, cloud에 나누어서 계층적으로 연산
--> data size, harware capability, DNN model, network quality, accuracy/latency tradeoff, energy, monetary cost 등에 따라 오프로딩 여부 결정

4) distributed offloading
--> 로컬에서 offloading & partitioning
--> 다른 방법들보다 분배와 최적화를 세분화

* 결론
- 정답은 없지만 각자의 상황에 맞는 적절한 방법과 하드웨어는 분명 존재한다
- 남들이 좋다는 것 덜컥 사용하지 말고 시스템을 잘 고려해서 적절한 방법과 하드웨어를 찾아야 한다
출처: 엣지 컴퓨팅(Edge Computing) 이란?
Chen, Jiasi, and Xukan Ran, "Deep learning with edge computing: A review", Proceedings of the IEEE 107.8 (2019): 1655-1674.
IMR AI팀 Tech Lead 이종훈님 NVIDIA MEETUP 발표자료


